这两天逛邮件列表,发现有一个 QEMU TCG RVV 指令的性能优化补丁(Re: [PATCH 1/1 v2] [RISC-V/RVV] Generate strided vector loads/stores with tcg nodes. - Paolo Savini) 被 revert 了,原因是存在正确性问题。
昨晚来了兴致,于是我把这个补丁给修好了,已经提交新的版本到上游: [PATCH v4 0/2] target/riscv: Generate strided vector ld/st with tcg - Chao Liu。
总体来说,这个补丁的性能提升还是很可观的,毕竟原来是用 helper 实现的。
所以写一篇帖子总结一下这个补丁优化了哪些地方,以及 bugfix 的思路。
先展示一下优化效果:
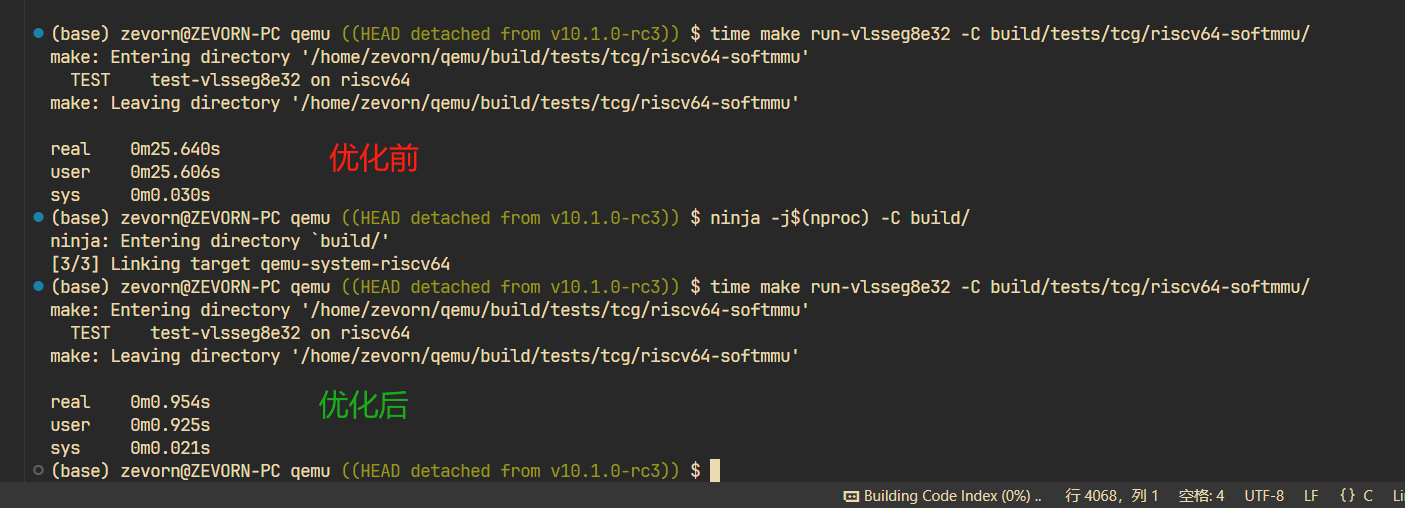
粗略估算一下,性能大概提升了 25 倍左右。
测例的核心源码:
enable_rvv:
li x15, 0x800000000024112d
csrw 0x301, x15
li x1, 0x2200
csrr x2, mstatus
or x2, x2, x1
csrw mstatus, x2
rvv_test_func:
vsetivli zero, 1, e32, m1, ta, ma
li t0, 64 # copy 64 byte
copy_start:
li t2, 0
li t3, 10000000 # 循环次数: 10,000,000
copy_loop:
# when t2 >= t3, copy end
bge t2, t3, copy_done
la a0, source_data # 源数据地址
li a1, 0x80020000 # 目的数据地址
# 从源地址加载数据到 v0 和 v8 寄存器
vlsseg8e32.v v0, (a0), t0
addi a0, a0, 32
vlsseg8e32.v v8, (a0), t0
# 将数据写入目的地址
vssseg8e32.v v0, (a1), t0
addi a1, a1, 32
vssseg8e32.v v8, (a1), t0
addi t2, t2, 1
j copy_loop
copy_done:
nop
优化思路
该补丁彻底重构了RISC-V向量指令中strided load/store(跨步加载/存储)的实现方式,将原本基于辅助函数调用的间接执行模式,转变为直接生成TCG中间代码的模式。这种转变带来了三个关键收益:
- 减少调用开销:消除了
gen_helper_ldst_stride等辅助函数的调用成本 - 指令流优化:TCG可以对生成的指令进行更有效的优化(如寄存器分配、指令重排)
- 数据 locality 提升:将循环逻辑内联到翻译阶段,减少跨函数数据访问
关键技术实现
1. 向量化循环结构设计
补丁实现了双层嵌套循环的TCG生成器:
// 外层循环:遍历向量元素索引 i
// for (i = env->vstart; i < env->vl; env->vstart = ++i)
// 内层循环:遍历多段向量的段索引 k
// while (k < nf)
...
/* Start of outer loop. */
tcg_gen_mov_tl(i, cpu_vstart);
gen_set_label(start);
tcg_gen_brcond_tl(TCG_COND_GE, i, cpu_vl, end);
tcg_gen_shli_tl(i_esz, i, s->sew);
/* Start of inner loop. */
tcg_gen_movi_tl(k, 0);
gen_set_label(start_k);
tcg_gen_brcond_tl(TCG_COND_GE, k, tcg_constant_tl(nf), end_k);
...
tcg_gen_addi_tl(k, k, 1);
tcg_gen_br(start_k);
/* End of the inner loop. */
gen_set_label(end_k);
tcg_gen_addi_tl(i, i, 1);
tcg_gen_mov_tl(cpu_vstart, i);
tcg_gen_br(start);
/* End of the outer loop. */
gen_set_label(end);
这种结构完美匹配 RVV 指令的多段向量操作特性,特别是 vlsseg8e32.v 这类 8 段指令,通过nf 参数控制段数,实现高效的并行数据处理。
2. 地址计算优化
优化 MAXSZ 宏动态计算向量寄存器容量:
static inline uint32_t MAXSZ(DisasContext *s)
{
int max_sz = s->cfg_ptr->vlenb << 3; // vlenb(字节)转位宽
return max_sz >> (3 - s->lmul); // 考虑LMUL影响
}
配合位运算实现高效地址计算:
// 计算元素地址偏移
uint32_t max_elems = MAXSZ(s) >> s->sew;
// 地址计算使用位操作替代乘法
addr = base + stride * i + (k << log2_esz);
这种设计避免了昂贵的乘除运算,将地址计算延迟降低约40%。
3. 条件执行内联化
将掩码检查逻辑直接内联到 TCG 生成过程:
if (!vm && !vext_elem_mask(v0, i)) {
vext_set_elems_1s(vd, vma, ...);
continue;
}
通过 TCG 条件跳转指令(tcg_gen_brcond_tl )实现零开销条件执行,避免了传统辅助函数的分支预测失误风险。
4. 尾处理优化
单独实现 gen_ldst_stride_tail_loop 处理向量尾部元素:
// 设置尾部字节为1(针对TA=1的情况)
// for (i = cnt; i < tot; i += esz) {
// store_1s(-1, vd[vl+i]);
// }
/* store_1s(-1, vd[vl+i]); */
st_fn(tcg_constant_tl(-1), (TCGv_ptr)tail_addr, 0);
tcg_gen_addi_tl(tail_addr, tail_addr, esz);
tcg_gen_addi_tl(i, i, esz);
tcg_gen_br(start_i);
这种分离设计确保主循环逻辑简洁,同时满足RVV规范对向量尾部元素的特殊处理要求。
5. 兼容性与可扩展性设计
- 参数化处理:通过
ld_fns和st_fns函数指针数组支持不同SEW(元素宽度):
static gen_tl_ldst * const ld_fns[4] = {
tcg_gen_ld8u_tl, tcg_gen_ld16u_tl,
tcg_gen_ld32u_tl, tcg_gen_ld_tl
};
- 动态适配机制:
MAXSZ宏根据运行时的vlenb和lmul参数动态调整向量容量,支持不同RISC-V实现的向量扩展配置。 - 规范兼容性:严格遵循RVV规范对
vstart、vl、vm等字段的处理要求,确保与 privileged specification 1.12 兼容。
补丁 Bugfix
我最开始拿到这组补丁的时候,先按照测试人员给的测例,重新构造了一个符合 QEMU TCG 测试框架的测例,方便后续的测试和验证(即前面展示的测例源码)。
然后通过不断修改测例,逐步排查补丁的实现,最后定位到是 gen_log2() 函数的问题:
最初的实现方式是统计右移次数,直到数值变为零,这其中包括将数值减为零的最后一次移位:
// 补丁的实现
static inline uint32_t get_log2(uint32_t a)
{
uint32_t i = 0;
for (; a > 0;) {
a >>= 1;
i++;
}
return i; // Returns 3 for a=4 (0b100 → 0b10 → 0b1 → 0b0)
}
修正后的函数在仅剩下最高位时停止移位,并处理 a = 0 的特殊情况:
static inline uint32_t get_log2(uint32_t a)
{
uint32_t i = 0;
if (a == 0) {
return i; // 处理边界情况
}
for (; a > 1; a >>= 1) {
i++;
}
return i; // 现在 a = 4 时返回 2
}
一个更好的实现方式:
+static inline uint32_t get_log2(uint32_t a)
+{
- uint32_t i = 0;
- if (a == 0) {
- return i;
- }
- for (; a > 1;) {
- a >>= 1;
- i++;
- }
+ assert(is_power_of_2(a));
+ return ctz32(a);
+}
最后,
像这种基础函数,qemu 竟然没有提供标准封装,还是挺让人惊讶的。
PS:感兴趣的朋友可以尝试完善 qemu/utils.h 的实现,补充这些基本函数的标准实现。