本文首发于 GTOC 微信公众号: 为何 EDKII 最新版会让 RISC-V Kernel 崩溃?
最近笔者在结合 QEMU 上游的补丁,搭建 QEMU RISC-V 的服务器参考平台(rvsp-ref),可以很顺利地启动 OpenEuler RISC-V 25.09,内核版本是 6.6。
不过操作系统镜像使用的 EDKII 版本是 stable/202502,现在最新版本的是 stable/202508。于是笔者尝试编译最新版的 EDKII 来启动 OS ,结果却遇到了意外:
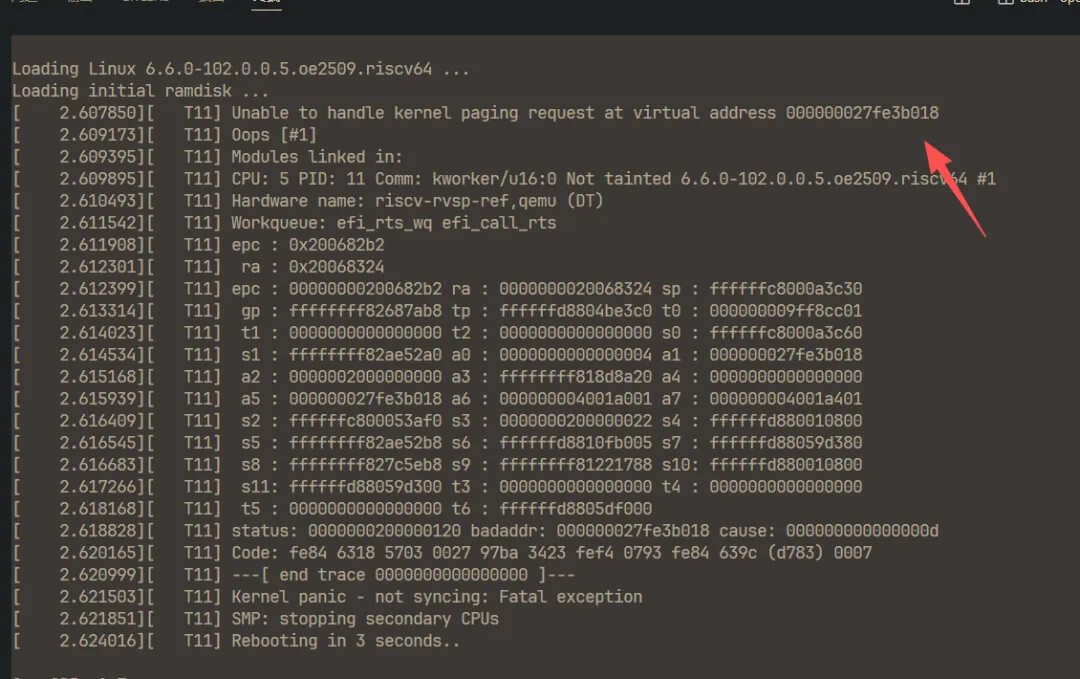
看内核报错日志,是在访问 0x27fe3b108 这个虚拟地址的时候,发现没有建立页表,于是导致 panic,case 是 0xd,对应异常类型是 load_page_fault。
为了进一步验证,我在 QEMU 启动参数中追加 -d int -D exec.log 用来捕获 Guest 的中断和异常流,于是得到以下信息:

可以看到,与内核报告的错误一致。笔者继续分析内核报错,触发错误的现场在 efi_call_rts 阶段。内核此时应该整在访问 EDKII 提供的 Runtime Services ,这也印证了,正是前面笔者换 EDKII 版本的操作,导致了这个问题。
QEMU rvsp-ref 的地址布局是兼容 virt board 的,所以笔者尝试用官方提供的启动脚本,在 virt 上用 EDKII 202508 来引导内核。结果很顺利地启动了起来:
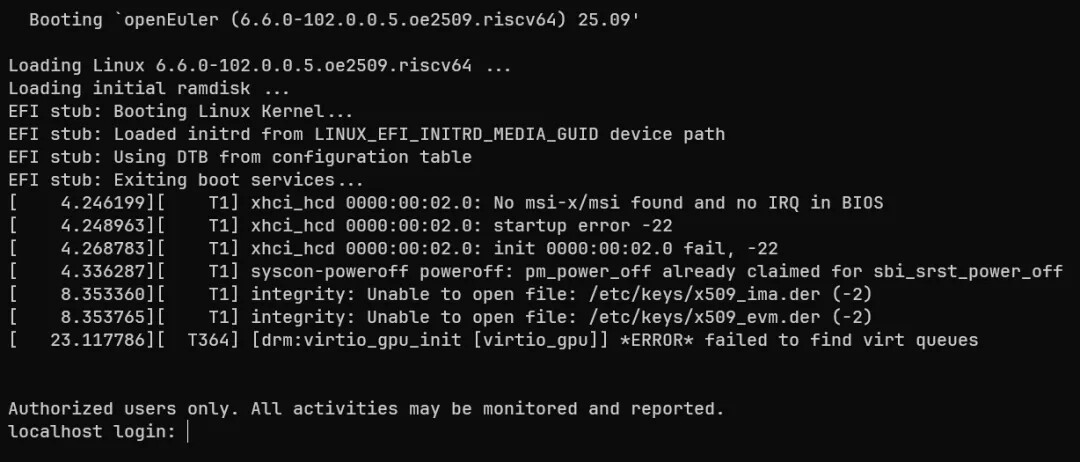
笔者的第一反应,是不是 QEMU rvsp-ref 实现有问题?但是转念一想,EDKII 202502 都可以正常引导呀。本着严谨的态度,笔者决定深入分析一下这个问题。
由于操作系统镜像是从官网下载,内核默认没有提供调试信息,所以笔者先通过 virt 正常启动 OS,然后修改 cmdline,追加了以下参数(或者在 grub2 中快速按 e 来操作):
earlycon=uart8250,mmio,0x10000000,115200 console=ttyS0,115200n8
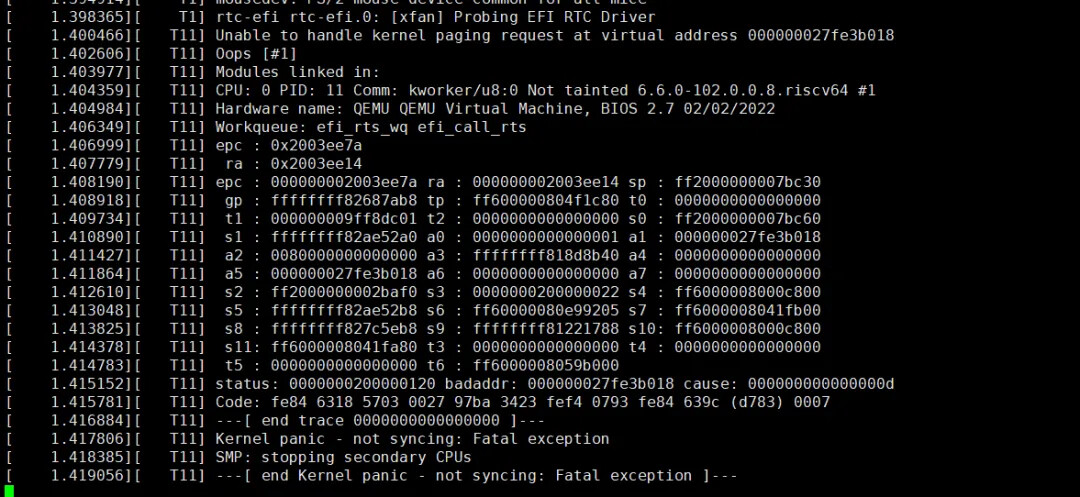
重启以后,运行 OS 可以获得更详细的报错(xfan 提供):
[ 3.318694][ T1] rtc-efi rtc-efi.0: [xfan] Probing EFI RTC Driver
[ 3.320581][ T72] Unable to handle kernel paging request at virtual address 000000027fe3b018
[ 3.321744][ T72] Oops [#1]
[ 3.321941][ T72] Modules linked in:
[ 3.322350][ T72] CPU: 1 PID: 72 Comm: kworker/u16:2 Not tainted 6.6.0-102.0.0.8.riscv64 #1
[ 3.323486][ T72] Hardware name: riscv-rvsp-ref,qemu (DT)
[ 3.324394][ T72] Workqueue: efi_rts_wq efi_call_rts
[ 3.325343][ T72] epc : 0x2003ee7a
[ 3.326398][ T72] ra : 0x2003ee14
[ 3.326752][ T72] epc : 000000002003ee7a ra : 000000002003ee14 sp : ff200000004c3c30
[ 3.327431][ T72] gp : ffffffff82687ab8 tp : ff60000081233900 t0 : 0000000000000000
[ 3.327811][ T72] t1 : 000000009ff8dc01 t2 : 0000000000000000 s0 : ff200000004c3c60
[ 3.328277][ T72] s1 : ffffffff82ae52a0 a0 : 0000000000000001 a1 : 000000027fe3b018
[ 3.328712][ T72] a2 : 0080000000000000 a3 : ffffffff818d8b40 a4 : 0000000000000000
[ 3.329473][ T72] a5 : 000000027fe3b018 a6 : 0000000000000000 a7 : 0000000000000000
[ 3.330366][ T72] s2 : ff20000000053af0 s3 : 0000000200000022 s4 : ff60000080010800
[ 3.330994][ T72] s5 : ffffffff82ae52b8 s6 : ff600000811f4a05 s7 : ff60000080ad3080
[ 3.332074][ T72] s8 : ffffffff827c5eb8 s9 : ffffffff81221788 s10: ff60000080010800
[ 3.332813][ T72] s11: ff60000080ad3000 t3 : 0000000000000000 t4 : 0000000000000000
[ 3.333490][ T72] t5 : 0000000000000000 t6 : ff600000805df000
[ 3.333911][ T72] status: 0000000200000120 badaddr: 000000027fe3b018 cause: 000000000000000d
[ 3.334660][ T72] Code: fe84 6318 5703 0027 97ba 3423 fef4 0793 fe84 639c (d783) 0007
注意第一条日志,似乎是和 EFI RTC Driver 有关:
[ 3.318694][ T1] rtc-efi rtc-efi.0: [xfan] Probing EFI RTC Driver
现在尝试禁用这个 Driver,在内核启动参数追加:
initcall_blacklist=efi_rtc_driver_init
重新运行,发现可以正常引导内核启动了:
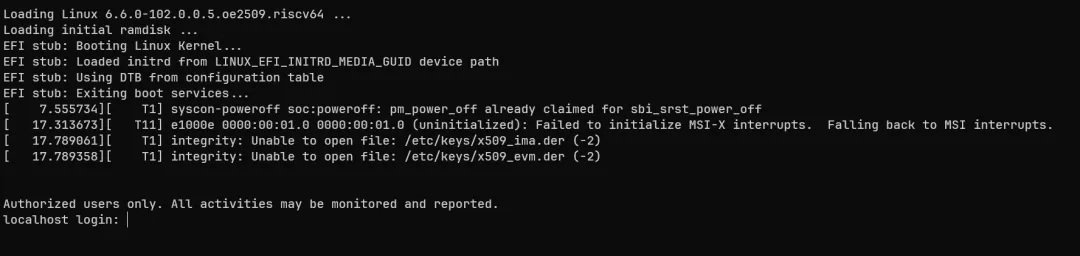
所以初步判断,引起内核 panic 的地方,大概率是内核调用 efi-rtc 服务的时候出的问题。接下来,我们深入腹地分析。
继续使用 QEMU gdbstub 来远程调试,连接上 gdb 以后,我们来观察内核崩溃时的位置,也就是 epc 指向的地址 0x2003ee7a 附近:
0x0000000000001000 in ?? ()
(gdb) x/10i 0x000000002003ee70
0x2003ee70: fld fs1,16(a4)
0x2003ee72: .insn 2, 0x8c28
0x2003ee74: li t0,21
0x2003ee76: .insn 4, 0x6a940fbb
0x2003ee7a: ld s9,448(sp)
0x2003ee7c: ld a0,40(a0)
0x2003ee7e: beqz s1,0x2003ee40
0x2003ee80: .insn 4, 0xc6d7fe8f
0x2003ee84: addi a0,a0,1
0x2003ee86: ld s10,416(sp)
(gdb)
看起来有点问题,两种可能的情况:大概率要等 EDKII 运行到某个阶段进行数据搬运以后,才能看到正确的指令流;或者崩溃的地方,本是一个虚拟地址。
先下个断点,继续往下观察。
(gdb) b *0x000000002003ee7a
Breakpoint 1 at 0x2003ee7a
(gdb) c
Continuing.
Thread 1 hit Breakpoint 1, 0x000000002003ee7a in ?? ()
重新查看崩溃处的指令:
(gdb) x/10i 0x000000002003ee70
0x2003ee70: sd a5,-24(s0)
0x2003ee74: addi a5,s0,-24
0x2003ee78: ld a5,0(a5)
=> 0x2003ee7a: lhu a5,0(a5)
0x2003ee7e: sext.w a4,a5
0x2003ee82: lui a5,0x10
0x2003ee84: addi a5,a5,-1
0x2003ee86: bne a4,a5,0x2003ee44
0x2003ee8a: li a5,0
0x2003ee8c: mv a0,a5
(gdb) p/x $a5
$1 = 0x27fe3b018
这里可以看出来,这条指令在尝试访问 0x27fe3b018 这个地址,与上面的崩溃日志吻合。
我们继续确认崩溃的地址类型:
(gdb) p/x (unsigned long)$satp >> 60
$2 = 0xa
(gdb) monitor gva2gpa 0x2003ee7a
gpa: 0x27fe6ee7a
显然,这个虚拟地址是 RISC-V 的 SV57 MMU 格式,并不是RISCV_VIRT_CODE.fd 直接映射到内存上的物理地址,所以我们刚启动 QEMU 时查看崩溃位置附近的指令是不正确的。
现在需要定位这条指令对应的源码,EDKII 不同于传统的 elf 二进制格式的程序,会做一些数据打包整合,所以我们得先定位到 EDKII 模块的 entry 地址。
这里为了方便定位 rtc 模块的入口地址,笔者修改 EDKII 的源码,使能调试信息打印,并重新编译它:
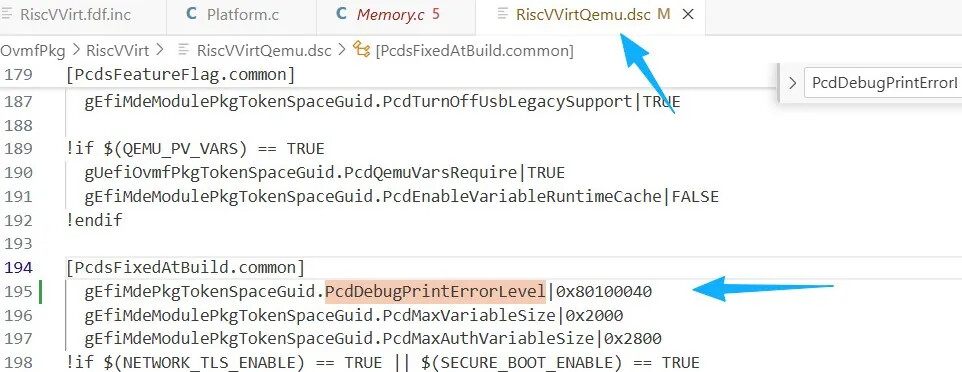
再次运行后,可以看到 EDKII 的打印日志:
Loading driver at 0x0027FE6C000 EntryPoint=0x0027FE6D04A RealTimeClock.efi
InstallProtocolInterface: BC62157E-3E33-4FEC-9920-2D3B36D750DF 27F82F998
ProtectUefiImageCommon - 0x7F82F0C0
- 0x000000027FE6C000 - 0x000000000000D000
看起来 0x27fe6ee7a 落在了这个地址段上,计算偏移为 0x2e7a。
反汇编 RealTimeClock.efi 文件来确认偏移是否正确:
$ riscv64-linux-gnu-objdump -b binary -m riscv -D RealTimeClock.efi
...
2e70: fef43423 sd a5,-24(s0)
2e74: fe840793 addi a5,s0,-24
2e78: 639c flw fa5,0(a5)
2e7a: 0007d783 lhu a5,0(a5)
2e7e: 0007871b sext.w a4,a5
2e82: 67c1 lui a5,0x10
2e84: 17fd addi a5,a5,-1 # 0xffff
2e86: faf71fe3 bne a4,a5,0x2e44
2e8a: 4781 li a5,0
2e8c: 853e mv a0,a5
...
和上面 gdb 的反汇编结果对比,发现两者是相同的,这证明我们的分析没有错,下一步来定位具体的源码。
两个办法,首先我们可以尝试加载包含了调试信息的 RealTimeClock.debug 文件到 gdb,确认代码是否一致:
$ gdb-multiarch RealTimeClock.debug
Reading symbols from RealTimeClock.debug...
(gdb) x/10i 0x2e70
0x2e70 <GetNextHob+118>: sd a5,-24(s0)
0x2e74 <GetNextHob+122>: addi a5,s0,-24
0x2e78 <GetNextHob+126>: ld a5,0(a5)
0x2e7a <GetNextHob+128>: lhu a5,0(a5)
0x2e7e <GetNextHob+132>: sext.w a4,a5
0x2e82 <GetNextHob+136>: lui a5,0x10
0x2e84 <GetNextHob+138>: addi a5,a5,-1
0x2e86 <GetNextHob+140>: bne a4,a5,0x2e44 <GetNextHob+74>
0x2e8a <GetNextHob+144>: li a5,0
0x2e8c <GetNextHob+146>: mv a0,a5
看起来大差不大,接下来使用 addr2line 工具来定位源码信息:
$ addr2line -e RealTimeClock.debug 0x2e70
/edk2/MdePkg/Library/DxeHobLib/HobLib.c:114
$ vim MdePkg/Library/DxeHobLib/HobLib.c
94 VOID *
95 EFIAPI
96 GetNextHob (
97 IN UINT16 Type,
98 IN CONST VOID *HobStart
99 )
100 {
101 EFI_PEI_HOB_POINTERS Hob;
102
103 ASSERT (HobStart != NULL);
104
105 Hob.Raw = (UINT8 *)HobStart;
106 //
107 // Parse the HOB list until end of list or matching type is found.
108 //
109 while (!END_OF_HOB_LIST (Hob)) {
110 if (Hob.Header->HobType == Type) {
111 return Hob.Raw;
112 }
113
114 Hob.Raw = GET_NEXT_HOB (Hob);
115 }
116
117 return NULL;
118 }
而关于 HOB ,在 EDKII 的打印日志里也有一个关键信息,笔者贴在下面:
HOBLIST address in DXE = 0x27FE3B018
这个就是内核在访问 efi-rtc 服务时试图访问的地址,出现了页错误。
由于笔者不了解 EDKII 的运行机制,此处推测, EDKII 启动内核时会不会传递一组页表信息交给内核做映射呢?如果会的话,是不是这个过程有问题导致这个地址未映射。
另外我们继续发散思维,从 QEMU 这边继续推导,发生页错误的地址,落在了 IMSIC_M 的地址空间,这是一块 mmio 地址:
static const MemMapEntry rvsp_ref_memmap[] = {
[RVSP_FLASH] = { 0x20000000, 0x4000000 },
[RVSP_IMSIC_M] = { 0x24000000, RVSP_IMSIC_MAX_SIZE },
[RVSP_IMSIC_S] = { 0x28000000, RVSP_IMSIC_MAX_SIZE },
[RVSP_PCIE_ECAM] = { 0x30000000, 0x10000000 },
[RVSP_PCIE_MMIO] = { 0x40000000, 0x40000000 },
[RVSP_DRAM] = { 0x80000000, 0xff80000000ull },
[RVSP_PCIE_MMIO_HIGH] = { 0x10000000000ull, 0x10000000000ull },
};
是否有这种可能性,QEMU 传递给 EDKII 的 DTB 有问题,导致映射出现问题?继续阅读 QEMU rvsp-ref 的源码:
static void create_fdt_one_imsic(RVSPMachineState *s, hwaddr base_addr,
uint32_t *intc_phandles, uint32_t msi_phandle,
bool m_mode, uint32_t imsic_guest_bits)
{
...
imsic_max_hart_per_socket = 0;
for (socket = 0; socket < socket_count; socket++) {
imsic_addr = base_addr + socket * RVSP_IMSIC_GROUP_MAX_SIZE;
// 具体关注这里
imsic_size = IMSIC_HART_SIZE(imsic_guest_bits) *
s->soc[socket].num_harts;
imsic_regs[socket * 4 + 0] = 0;
imsic_regs[socket * 4 + 1] = cpu_to_be32(imsic_addr);
imsic_regs[socket * 4 + 2] = 0;
imsic_regs[socket * 4 + 3] = cpu_to_be32(imsic_size);
if (imsic_max_hart_per_socket < s->soc[socket].num_harts) {
imsic_max_hart_per_socket = s->soc[socket].num_harts;
}
}
...
}
发现 IMSIC 是通过 hart 数量来动态确定地址范围的,所以笔者推测可能是 QEMU 并没有把 IMSIC 的地址范围在 DTB 里面全部覆盖到,导致存在地址空腔被 EDKII 误认为是正常可用的内存空间,于是用来放指令或者数据了。
所以笔者这里尝试修改 QEMU 源码,让生成的 DTB 将 IMSIC 的地址范围全部占满。重新运行 EDKII 引导内核,仍然 panic,因此问题不在这里。
考虑 virt 可以正常启动,所以笔者尝试对比两边的运行日志,看看有哪些差异,但是大致上是相同的。
到这里还没有别的方法呢?
可以尝试通过 gdb 来对比关键指令流,也可以通过 QEMU execlog 插件记录关键指令流,进行差异的分析,先选择前者,分析的数据如下:
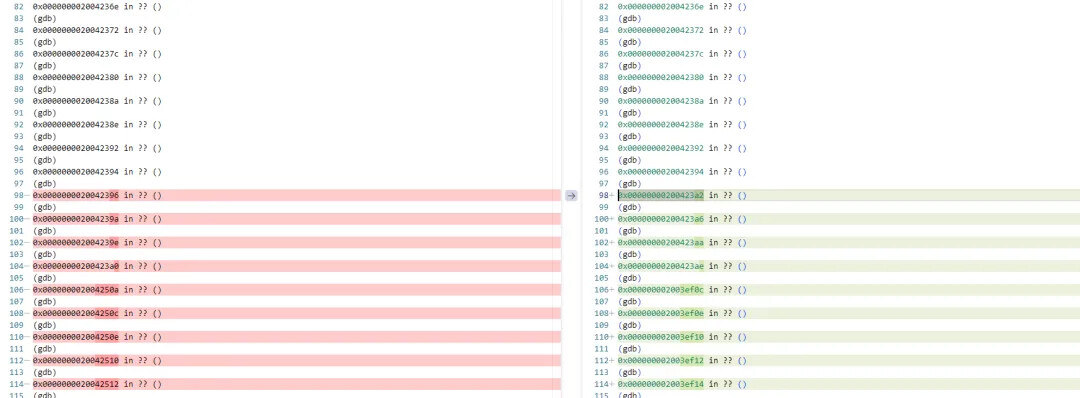
xfan 提供了一些关键发现:
-
virt和rvsp-ref 的efi驱动调用efi_call_virt(get_time, args->GET_TIME.time, args->GET_TIME.capabilities);都是通过 jalr a5 跳转到 0x2003d6b8 这个位置,这是一个efi服务。
-
此时 virt 和 rvsp-ref 两个 machine 均无法访问 0x27fe3b018 这个地址(unmap)。
-
virt 和 rvsp-ref 在 efi 代码中的流程不太一样,虽然都是 0x2003d6b8 作为入口。virt 机器不会去访问 0x27fe3b018 这个地址。
于是笔者和 xfan 反向定位到源码,流程如下:
(gdb) monitor gva2gpa 0x0000000020042394 # virt和rvsp-ref分支的地址
gpa: 0x27fe72394
# 偏移计算
>>> hex(0x27fe72394-0x000000027FE6C000)
'0x6394'
# 源码信息
xiaofan@xfan-ubuntu2404-devel:~/workspace/edk2$ riscv64-linux-gnu-addr2line -e Build/RiscVVirtQemu/DEBUG_GCC/RISCV64/RealTimeClock.debug 0x6394
/edk2/UefiCpuPkg/Library/BaseRiscV64CpuTimerLib/CpuTimerLib.c:161
源码如下:
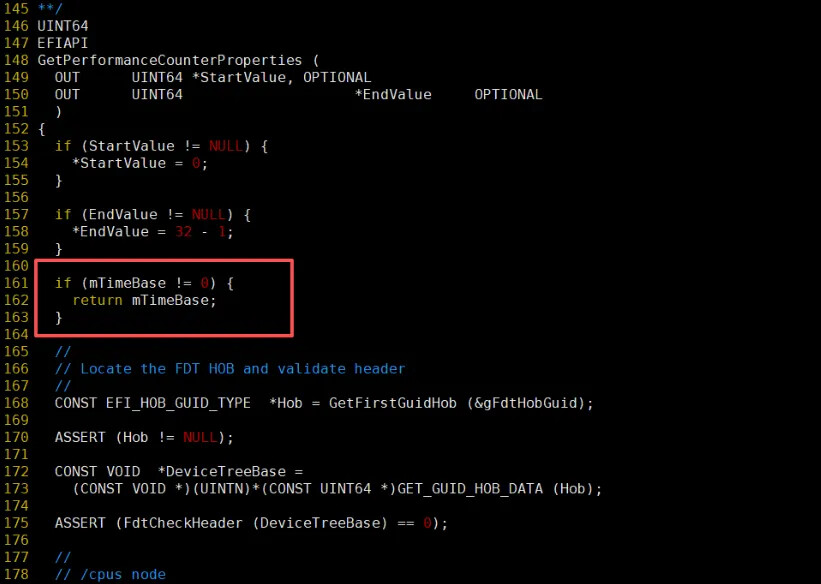
对于 virt,当内核访问 efi-rtc 服务,调用到这里时, mTimeBase 是有值的,所以直接返回了,但是对于 rvsp-ref 这里 mTimeBase 的值为 0,所以继续往下执行,遇到的了 panic。
通过静态分析代码,发现 GetFirstGuidHob() 函数调用了 GetNextHob() 函数,崩溃发生在这个函数内部。
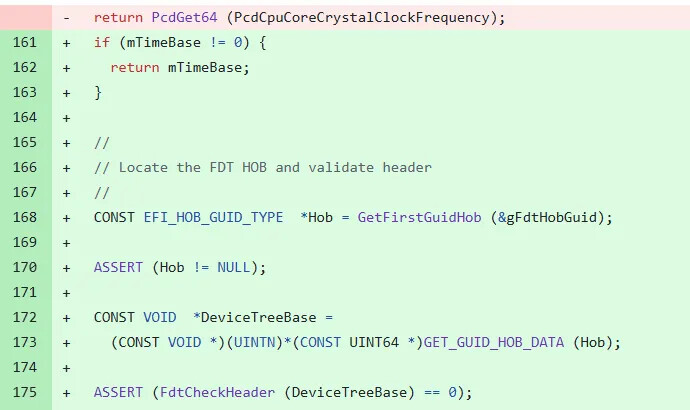
实际上,通过阅读这段代码,并结合全局搜索,发现初始化 mTimeBase 的流程,就是 165 行往下的代码逻辑,通过解析 DTB 的 timebase-frequency 属性获取:
UINT64
EFIAPI
GetPerformanceCounterProperties (
OUT UINT64 *StartValue, OPTIONAL
OUT UINT64 *EndValue OPTIONAL
)
{
...
//
// Locate the FDT HOB and validate header
//
Hob = GetFirstGuidHob (&gFdtHobGuid);
if (Hob) {
FdtBase = (CONST VOID *)(UINTN)*(CONST UINT64 *)GET_GUID_HOB_DATA (Hob);
} else {
//
// Get the FDT address from the SEC HOB
//
Hob = GetFirstGuidHob (&SecHobDataGuid);
ASSERT (Hob != NULL);
SecData = (RISCV_SEC_HANDOFF_DATA *)GET_GUID_HOB_DATA (Hob);
FdtBase = (CONST VOID *)SecData->FdtPointer;
}
ASSERT (FdtBase != NULL);
ASSERT (FdtCheckHeader ((VOID *)(UINTN)FdtBase) == 0);
//
// /cpus node
//
INT32 Node = FdtSubnodeOffsetNameLen (
FdtBase,
0,
"cpus",
sizeof ("cpus") - 1
);
ASSERT (Node >= 0);
//
// timebase-frequency property
//
INT32 Len;
CONST FDT_PROPERTY *Prop =
FdtGetProperty (FdtBase, Node, "timebase-frequency", &Len);
ASSERT (Prop != NULL && Len == sizeof (UINT32));
//
// Device-tree cells are big-endian
//
TimeBase = SwapBytes32 (*(CONST UINT32 *)Prop->Data);
ASSERT (TimeBase != 0);
//
// Save the time base for later use. Note that the mTimeBase maybe zero if
// this library is stored in read-only memory.
//
mTimeBase = TimeBase;
return TimeBase;
}
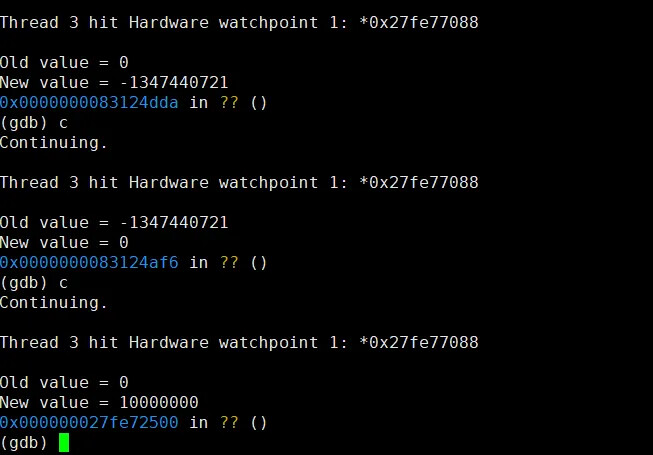
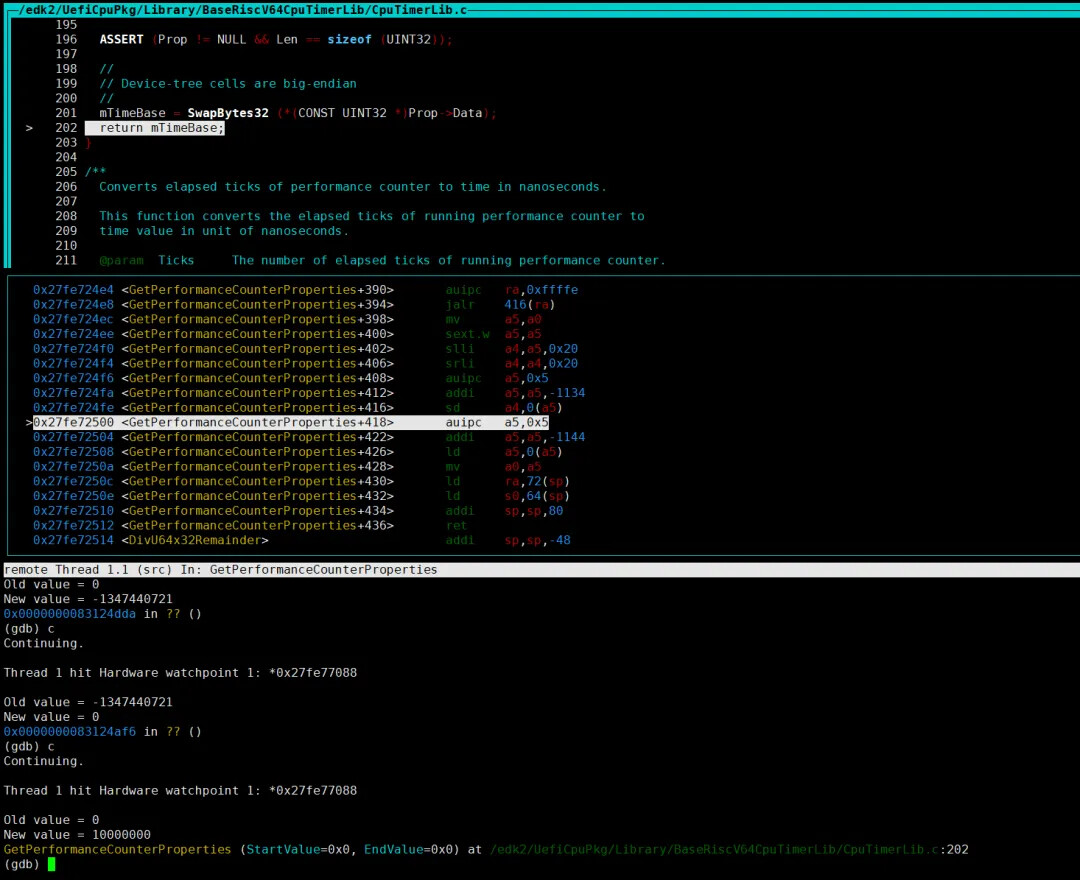
接下来,调试思路就比较清晰了,我们可以为 mTimeBase 这个全局变量增加监视点,看一下 virt 和 rvsp-ref 上初始化流程有什么差异。
经过分析,virt 可以捕获到修改 mTimeBase 的地方,但是 rvsp-ref 不行:
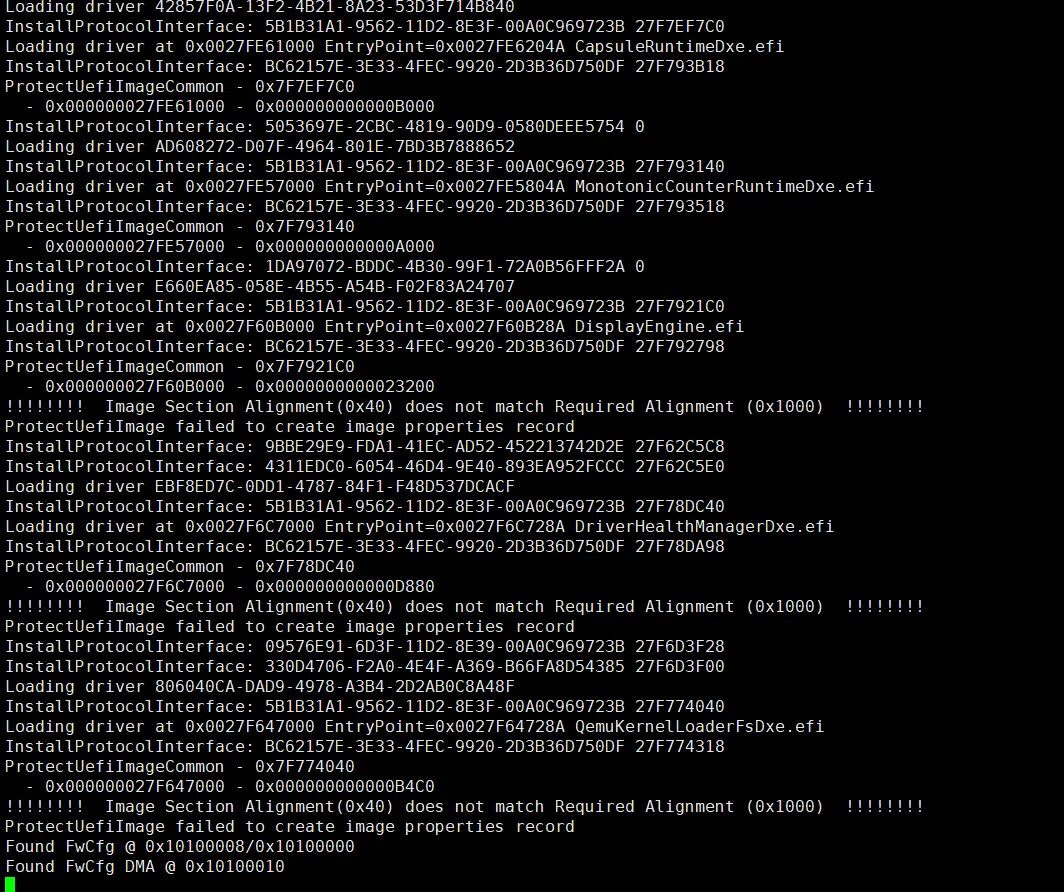
此时,查看 EDKII 的启动日志,发现还在初始化阶段:
我们给 gdb 加载相应模块的调试符号,查看此时 mTimeBase 在哪里被赋值的:
我们来观察一下调用栈,看看是在哪个模块初始化的时候被调用的:
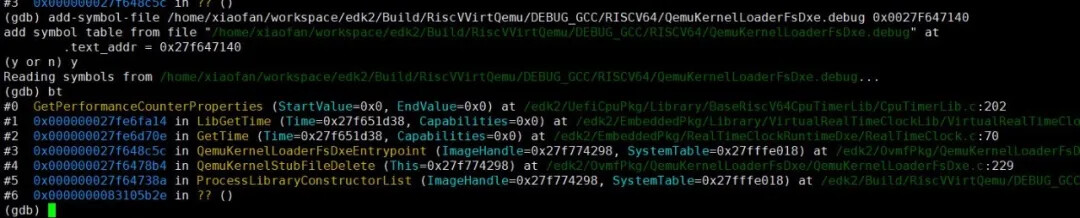
我们关注 QemuKernelLoaderFsDxeEntrypoint() 这个函数:
EFI_STATUS
EFIAPI
QemuKernelLoaderFsDxeEntrypoint (
IN EFI_HANDLE ImageHandle,
IN EFI_SYSTEM_TABLE *SystemTable
)
{
UINTN BlobIdx;
KERNEL_BLOB_ITEMS *BlobItems;
KERNEL_BLOB *Blob;
EFI_STATUS Status;
EFI_STATUS FetchStatus;
EFI_HANDLE FileSystemHandle;
EFI_HANDLE InitrdLoadFile2Handle;
if (!QemuFwCfgIsAvailable ()) {
return EFI_NOT_FOUND;
}
// 这里会调用 GetTime
Status = gRT->GetTime (&mInitTime, NULL /* Capabilities */);
if (EFI_ERROR (Status)) {
DEBUG ((DEBUG_ERROR, "%a: GetTime(): %r\n", __func__, Status));
return Status;
}
...
}
这段代码需要先过一个 fw_cfg 检查,然后才会调用 GetTime(),注意前面 EDKII 启动日志那里,有一段打印:
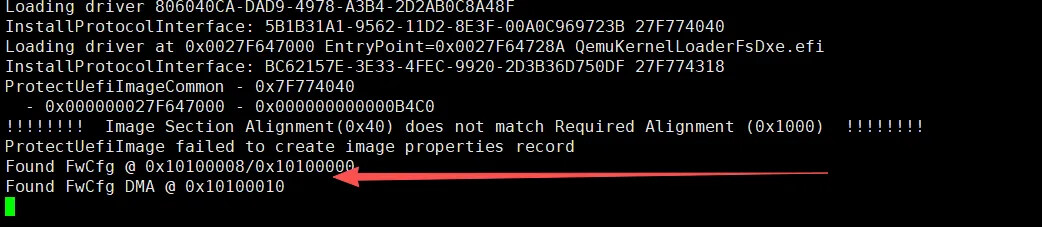
会不会和 fw_cfg 有关呢?
fw_cfg 是 QEMU 提供的一个组件,用来给内核传递启动参数,也可以用于 Guest 识别 QEMU 平台。rvsp-ref 的设计是没有包含 fw_cfg 的。
很显然,因为 EDKII 检查到 rvsp-ref 并不包含 fw_cfg 组件,所以直接返回了,错过了 GetTime(),而这个函数内部会对 mTimeBase 进行第一次初始化。
那为什么在内核调用 efi-rtc 服务的时候,因为 mTimeBase 没有初始化而重新尝试对它进行初始化的时候,会发生页错误呢?
问题回到 EDKII 的 HOB 这里,也就是我们前面发现崩溃的地方。
我们来简单分析一下 HOB 的设计:
// MdePkg/Include/Library/HobLib.h
/** @file
Provides services to create and parse HOBs. Only available for PEI
and DXE module types.
The HOB Library supports the efficient creation and searching of HOBs
defined in the PI Specification.
A HOB is a Hand-Off Block, defined in the Framework architecture, that
allows the PEI phase to pass information to the DXE phase. HOBs are position
independent and can be relocated easily to different memory locations.
Copyright (c) 2006 - 2018, Intel Corporation. All rights reserved.<BR>
SPDX-License-Identifier: BSD-2-Clause-Patent
**/
根据 HobLib.h 开头的注释,这表明 HOB(Hand-Off Block) 的主要设计目的是在 PEI 阶段和 DXE 阶段之间传递信息而不是为了在 runtime 阶段使用。
来看一下 AI 的分析:

标准做法,应该是把必要信息复制到 runtime 的内存:

而 EDKII 的设计,没有考虑到不包含 fw_cfg 组件的情况,导致一些必要的组件,比如 efi_rtc 没有在初始化阶段,正确获取到 runtime 时需要使用的数据。
这里笔者和 xfan 分别尝试禁用 EDKII 的 fw_cfg 检查和 QEMU virt 的fw_cfg 组件,前者可以在 virt 上复现遇到的内核 panic,后者可以保证 rvsp-ref 可以正常启动内核。
另外我们也尝试通过 gdb 在 virt 上运行到内核调用 efi-rtc 服务时,强制将 mTimeBase 修改为 0 ,也可以触发内核 panic:
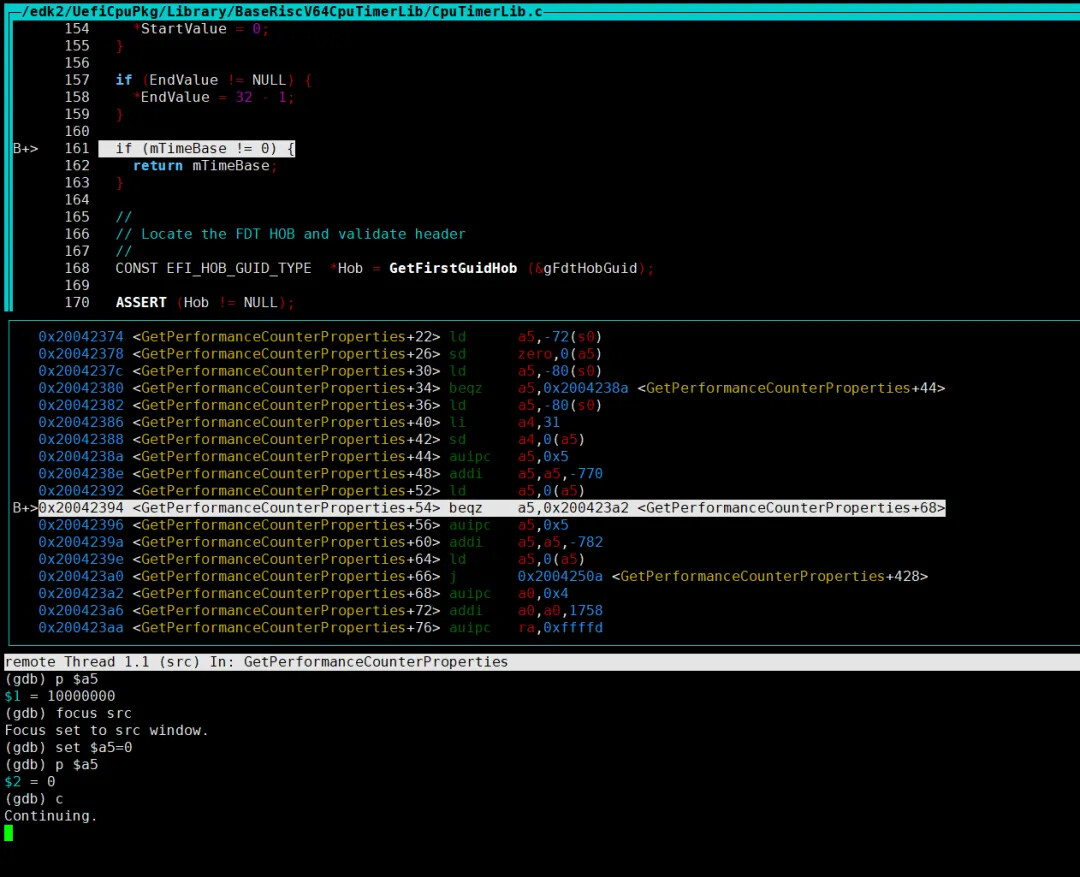
可以看到,报错现象与 rvsp-ref 一致:
考虑 EDKII stable/202502 可以正常运行,我们对比了两个 tag 的源码,发现五月份上游引入了一个补丁,为 efi-rtc 增加了从 DTB 解析定时器频率的功能,以前是传递的常量:
目前还不确定这样实现有没有什么问题,我们将这个潜在 Bug 报告到了 EDKII 上游:
到此,困扰了笔者几天的问题,终于水落石出!