用GCC 16.1.0编译llama.cpp b9264,开启了向量指令集,设置了流水线优化,开启LTO,编译过程如下,我用fish
cd /mnt/nas/llama.cpp/build
rm -rf *
set -gx CC /opt/gcc-16.1.0/bin/gcc
set -gx CXX /opt/gcc-16.1.0/bin/g++
set -gx M_ARCH "rv64imafdc_zicntr_zicsr_zifencei_zihpm_zfh_xtheadba_xtheadbb_xtheadbs_xtheadcmo_xtheadcondmov_xtheadfmemidx_xtheadmac_xtheadmemidx_xtheadmempair_xtheadsync_xtheadvector"
set -gx CFLAGS "-O3 -mcpu=xt-c910 -march=$M_ARCH -falign-loops=64 -falign-functions=64 -falign-jumps=64 \
--param l1-cache-size=64 --param l1-cache-line-size=64 --param simultaneous-prefetches=4 \
-funroll-loops -fvariable-expansion-in-unroller"
set -gx CXXFLAGS "-O3 -mcpu=xt-c910 -march=$M_ARCH -falign-loops=64 -falign-functions=64 -falign-jumps=64 \
--param l1-cache-size=64 --param l1-cache-line-size=64 --param simultaneous-prefetches=4 \
-funroll-loops -fvariable-expansion-in-unroller"
set -gx LDFLAGS "-L/opt/gcc-16.1.0/lib -L/opt/gcc-16.1.0/lib64 -Wl,-rpath=/opt/gcc-16.1.0/lib:/opt/gcc-16.1.0/lib64"
set -gx LIBRARY_PATH /opt/gcc-16.1.0/lib /opt/gcc-16.1.0/lib64 $LIBRARY_PATH
set -gx LD_LIBRARY_PATH /opt/gcc-16.1.0/lib /opt/gcc-16.1.0/lib64 $LD_LIBRARY_PATH
set -gx LDFLAGS "-L/opt/gcc-16.1.0/lib -L/opt/gcc-16.1.0/lib64 -Wl,-rpath=/opt/gcc-16.1.0/lib:/opt/gcc-16.1.0/lib64"
cmake .. \
-DCMAKE_BUILD_TYPE=Release \
-DLLAMA_BUILD_TESTS=OFF \
-DGGML_OPENMP=ON \
-DOpenMP_C_FLAGS="-fopenmp" \
-DOpenMP_CXX_FLAGS="-fopenmp" \
-DOpenMP_C_LIB_NAMES="gomp" \
-DOpenMP_CXX_LIB_NAMES="gomp" \
-DOpenMP_gomp_LIBRARY="/opt/gcc-16.1.0/lib/libgomp.so" \
-DGGML_RVV=OFF \
-DGGML_XTHEADVECTOR=ON \
-DGGML_LTO=ON
# 手工添加webui文件
cp -r /mnt/nas/dist tools/ui/
# 禁止Vector 1.0代码,几年前的小破烂没这功能
sed -i 's/__riscv_v_intrinsic/__riscv_v/g' ../ggml/src/ggml-cpu/arch/riscv/quants.c
cmake --build . --config Release -j4
编译好的程序确实支持xtheadvector
debian@revyos-lpi4a /m/n/llama.app-b9264-lto-shared> readelf -A libggml-cpu.so.0.12.0
Attribute Section: riscv
File Attributes
Tag_RISCV_stack_align: 16-bytes
Tag_RISCV_arch: "rv64i2p1_m2p0_a2p1_f2p2_d2p2_c2p0_zicntr2p0_zicsr2p0_zifencei2p0_zihpm2p0_zmmul1p0_zaamo1p0_zalrsc1p0_zfh1p0_zfhmin1p0_zca1p0_zcd1p0_xtheadba1p0_xtheadbb1p0_xtheadbs1p0_xtheadcmo1p0_xtheadcondmov1p0_xtheadfmemidx1p0_xtheadmac1p0_xtheadmemidx1p0_xtheadmempair1p0_xtheadsync1p0_xtheadvector1p0"
Tag_RISCV_unaligned_access: Unaligned access
Tag_RISCV_priv_spec: 1
Tag_RISCV_priv_spec_minor: 11
debian@revyos-lpi4a /m/n/llama.app-b9264-lto-shared> objdump -d libggml-cpu.so | grep -E "th\.v|vset" | head -n 30
c94c: 000077d7 th.vsetvli a5,zero,e8,m1,d1
c952: 03067107 th.vleff.v v2,(a2)
c958: 0306f087 th.vleff.v v1,(a3)
c95c: 662081d7 th.vmsne.vv v3,v2,v1
c960: 62203057 th.vmseq.vi v0,v2,0
c964: c2002773 csrr a4,th.vl
c968: 6a01a257 th.vmor.mm v4,v0,v3
c96c: 56402557 th.vmfirst.m a0,v4
c99c: 000077d7 th.vsetvli a5,zero,e8,m1,d1
c9a2: 0308f287 th.vleff.v v5,(a7)
c9a8: 030e7307 th.vleff.v v6,(t3)
c9ac: 665303d7 th.vmsne.vv v7,v5,v6
c9b0: 62503457 th.vmseq.vi v8,v5,0
c9b4: c2002ef3 csrr t4,th.vl
c9b8: 6a83a4d7 th.vmor.mm v9,v8,v7
c9bc: 56902f57 th.vmfirst.m t5,v9
c9ec: 000077d7 th.vsetvli a5,zero,e8,m1,d1
c9f2: 0302f507 th.vleff.v v10,(t0)
c9f8: 03037587 th.vleff.v v11,(t1)
c9fc: 66a58657 th.vmsne.vv v12,v10,v11
ca00: 62a036d7 th.vmseq.vi v13,v10,0
ca04: c20023f3 csrr t2,th.vl
ca08: 6ad62757 th.vmor.mm v14,v13,v12
ca0c: 56e02557 th.vmfirst.m a0,v14
ca3c: 000077d7 th.vsetvli a5,zero,e8,m1,d1
ca42: 030f7787 th.vleff.v v15,(t5)
ca48: 030ff807 th.vleff.v v16,(t6)
ca4c: 66f808d7 th.vmsne.vv v17,v15,v16
ca50: 62f03957 th.vmseq.vi v18,v15,0
ca54: c20026f3 csrr a3,th.vl
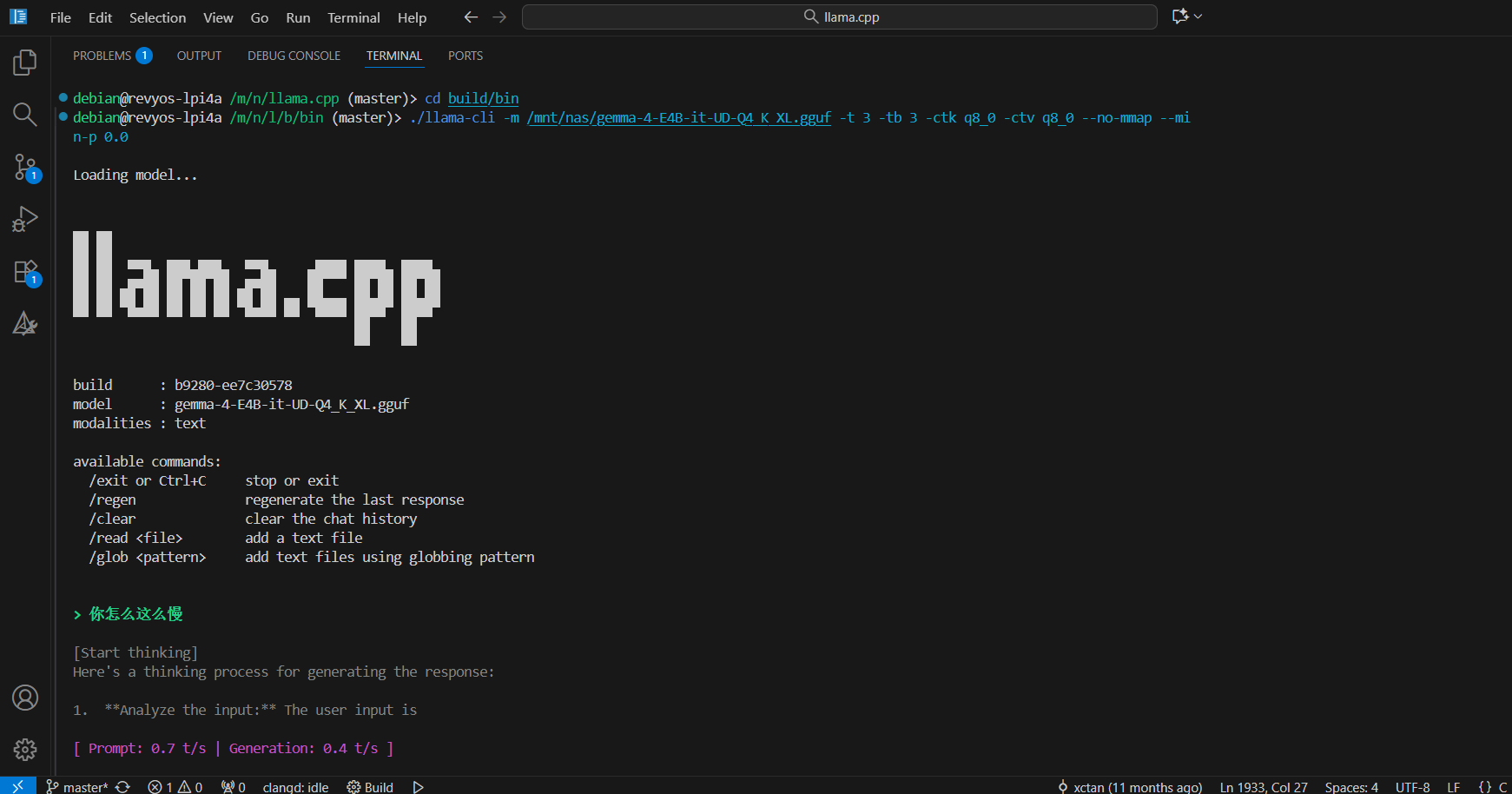
运行谷歌的芝麻4 E4B,使用3个核心的速度是0.4t/s,使用4核速度0.5t/s
debian@revyos-lpi4a /m/n/llama.app-b9264-lto-shared> ./llama-cli \
-m /mnt/nas/gemma-4-E4B-it-Q4_0.gguf \
-t 3 \
-tb 3 \
-ctk q8_0 \
-ctv q8_0 \
--no-mmap \
--min-p 0.0
Loading model...
▄▄ ▄▄
██ ██
██ ██ ▀▀█▄ ███▄███▄ ▀▀█▄ ▄████ ████▄ ████▄
██ ██ ▄█▀██ ██ ██ ██ ▄█▀██ ██ ██ ██ ██ ██
██ ██ ▀█▄██ ██ ██ ██ ▀█▄██ ██ ▀████ ████▀ ████▀
██ ██
▀▀ ▀▀
build : b9274-52fb93a2b
model : gemma-4-E4B-it-Q4_0.gguf
modalities : text
available commands:
/exit or Ctrl+C stop or exit
/regen regenerate the last response
/clear clear the chat history
/read <file> add a text file
/glob <pattern> add text files using globbing pattern
> 你现在运行在TH1520上,16GB内存,反应缓慢,什么原因?
[Start thinking]
Here's a thinking process to construct the answer:
1. **Analyze the Request:** The user is presenting a scenario: "I am running on TH1520, 16GB RAM, and the reaction/response is slow. Why?"
* *Context:* The user is likely referring to a server, computing environment, or specific piece of hardware/software (TH1520).
* *Problem:* Slowness/slow reaction time.
* *Constraints provided:* TH1520 (likely the hardware model/architecture), 16GB RAM.
2. **Identify the Core Problem (Symptom):** Slowness.
3. **Determine Possible Causes (The "Why"):** Since I am an AI model and cannot directly access the hardware/software configuration, I must provide a comprehensive list of *potential* technical bottlenecks.
* *Hardware Constraints (TH15
[ Prompt: 0.6 t/s | Generation: 0.4 t/s ]
> 继续吧
[Start thinking]
Here's a thinking process that leads to the suggested response:
1. **Analyze the Request:** The user is asking for potential reasons why a system running on a specific setup (TH1520, 16GB RAM) would be experiencing slow performance ("反应缓慢"). The implied context is a computing environment where the AI (or a running process) is operating.
2. **Identify the Key Components & Constraints:**
* **System:** TH1520 (This is likely a specific type of embedded system, single-board computer, or proprietary server/device. Its performance characteristics are crucial but unknown.)
* **Memory:** 16GB RAM (This is generally sufficient for many tasks, but not necessarily for heavy AI/computation.)
* **Symptom:** Slow responsiveness ("反应缓慢").
* **Goal:** Provide a comprehensive list of possible causes.
3. **Categorize Potential Bottlenecks (The 4 Pillars of Performance):**
* **A. Hardware Limitations (The Physical Machine):**
* CPU Speed/Type (Is the TH1520 processor powerful enough?)
* Storage I/O (Is it using slow HDD, or is the SSD bottlenecked?)
* Network Latency (If the task involves external communication.)
* Thermals (Is it overheating? This causes throttling.)
* **B. Software/OS Issues (The Environment):**
* Operating System Overhead (Too many background processes, resource leaks.)
* Drivers (Are the drivers outdated or incompatible?)
* Resource Allocation (Is the application poorly optimized? Is it fighting with other processes?)
1更:
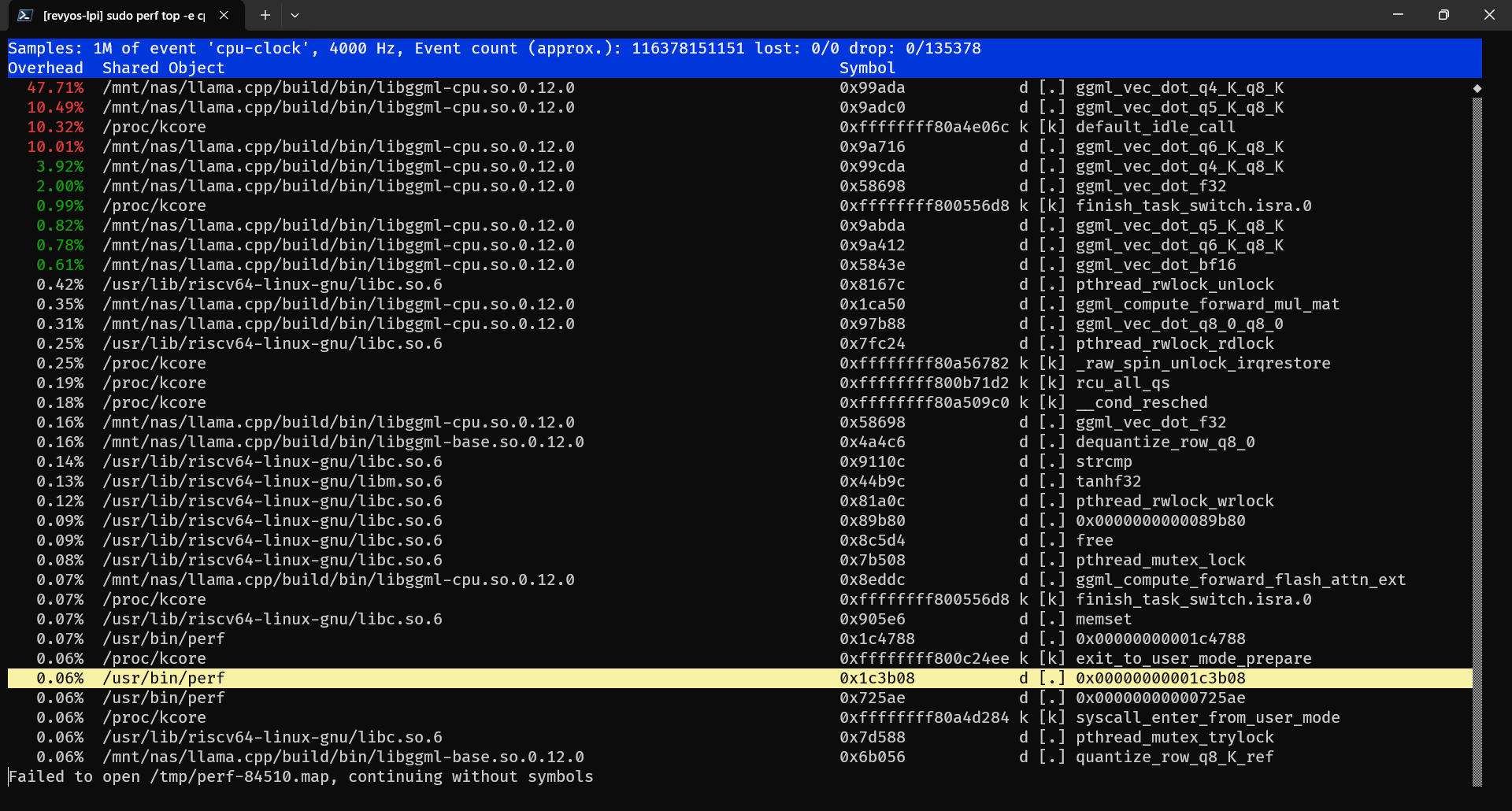
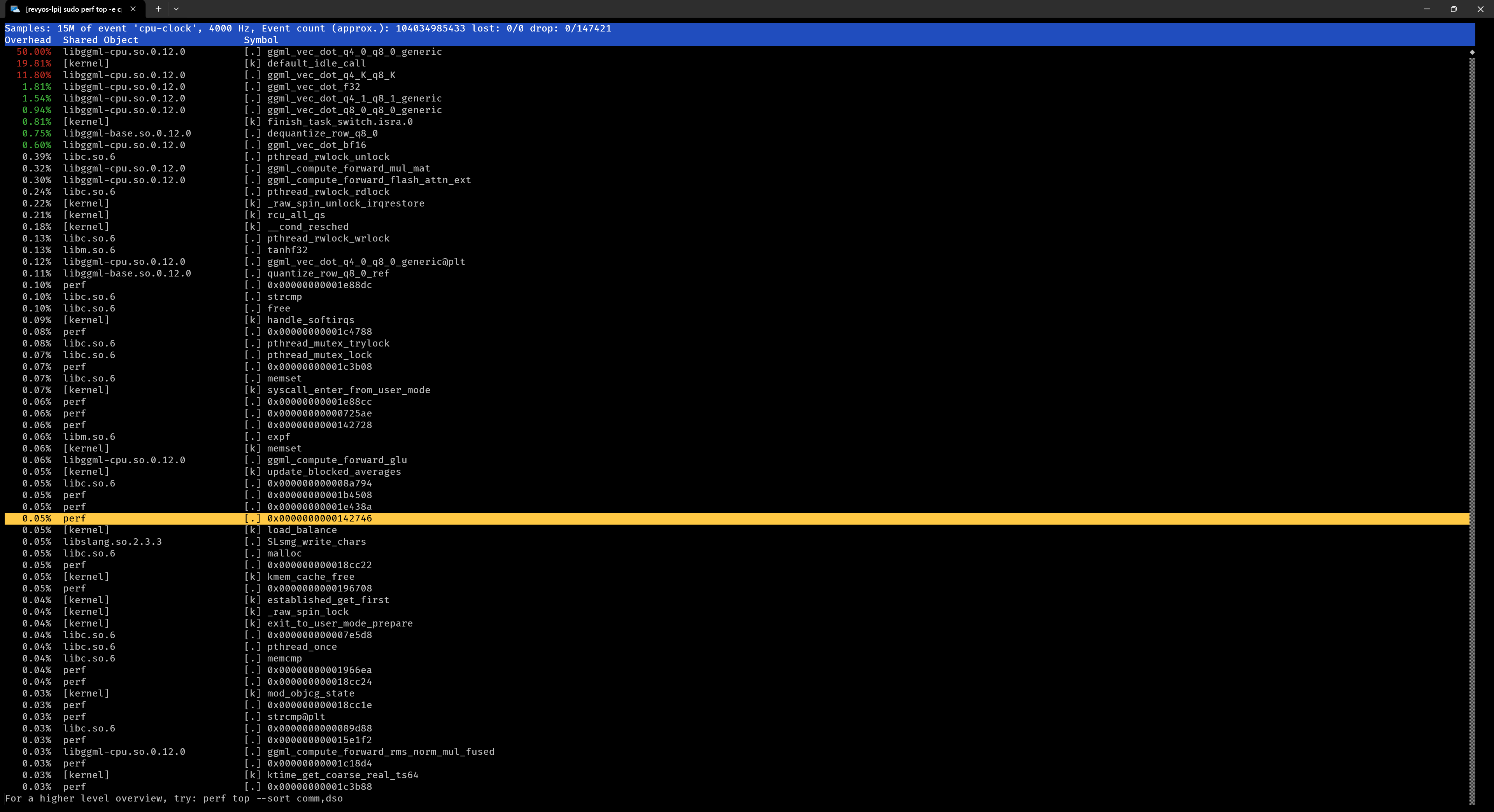
这是3核心的perf采样,ggml_vec_dot_q4_0_q8_0_generic 这个函数占了50%时间,它是标量指令函数
用AI写段脚本判断
#!/bin/bash
# ==================================================================
# Lichee Pi 4A (TH1520) - llama.cpp 向量算子真假硬核检测工具
# ==================================================================
# 默认检测当前目录下的库,也可以通过参数指定路径
SO_FILE=${1:-"libggml-cpu.so"}
if [ ! -f "$SO_FILE" ]; then
echo "❌ 错误: 找不到目标动态库文件: $SO_FILE"
echo "用法: bash check_vector.sh [path/to/libggml-cpu.so]"
exit 1
fi
echo "=================================================================="
echo " 🔍 正在深度解剖: $SO_FILE"
echo " 🔀 扫描目标: 所有全局导出的矩阵点积算子 (ggml_vec_dot_*)"
echo "=================================================================="
printf "%-38s | %-12s | %s\n" "核心算子函数名" "起始物理地址" "核心硬件执行状态"
echo "------------------------------------------------------------------"
# 1. 用 nm 捞出所有非 generic 结尾的全局定义函数
nm -D --defined-only "$SO_FILE" | grep "ggml_vec_dot_" | while read -r addr type name; do
start_addr="0x$addr"
# 2. 静态切片 256 字节(十六进制 0x100),足以容纳函数头部的初始化和核心循环
stop_addr=$(printf "0x%x" $((16#$addr + 256)))
# 3. 强行拉出该函数肉身的反汇编代码
asm_clip=$(objdump -d --start-address=$start_addr --stop-address=$stop_addr "$SO_FILE" 2>/dev/null)
# 4. 正则硬核过筛特征码:
# - th.v : 平头哥专属特有向量前缀
# - vset : 标准 RVV 的 vsetvli / vsetivli 矢量长度设置
# - \s+v[0-9]+ : 汇编指令中出现了 v0 ~ v31 向量寄存器
if echo "$asm_clip" | grep -E -q "th\.v|vset|\s+v[0-9]+"; then
status="\033[32m🟢 真向量 (满血压榨硬件加速)\033[0m"
else
# 5. 如果没有向量指令,进一步抓取它是不是一个直接 Jump 扔给 generic 的桩函数
if echo "$asm_clip" | grep -q -E "j[[:space:]]+.*generic"; then
status="\033[31m🔴 假把戏 (桩函数·直通标量地狱)\033[0m"
else
status="\033[33m🟡 纯标量 (无内耗·但无向量加速)\033[0m"
fi
fi
printf "%-38s | %-12s | b%b\n" "$name" "$start_addr" "$status"
done
echo "=================================================================="
==================================================================
🔍 正在深度解剖: libggml-cpu.so
🔀 扫描目标: 所有全局导出的矩阵点积算子 (ggml_vec_dot_*)
==================================================================
核心算子函数名 | 起始物理地址 | 核心硬件执行状态
------------------------------------------------------------------
ggml_vec_dot_bf16 | 0x00000000000583c0 | b🟡 纯标量 (无内耗·但无向量加速)
ggml_vec_dot_f16 | 0x0000000000058580 | b🟡 纯标量 (无内耗·但无向量加速)
ggml_vec_dot_f32 | 0x0000000000058700 | b🟢 真向量 (满血压榨硬件加速)
ggml_vec_dot_iq1_m_q8_K | 0x00000000000a6cc0 | b🔴 假把戏 (桩函数·直通标量地狱)
ggml_vec_dot_iq1_m_q8_K_generic | 0x000000000003e740 | b🟡 纯标量 (无内耗·但无向量加速)
ggml_vec_dot_iq1_s_q8_K | 0x00000000000a6c80 | b🔴 假把戏 (桩函数·直通标量地狱)
ggml_vec_dot_iq1_s_q8_K_generic | 0x000000000003e300 | b🟡 纯标量 (无内耗·但无向量加速)
ggml_vec_dot_iq2_s_q8_K | 0x00000000000a6d00 | b🔴 假把戏 (桩函数·直通标量地狱)
ggml_vec_dot_iq2_s_q8_K_generic | 0x000000000003d700 | b🟡 纯标量 (无内耗·但无向量加速)
ggml_vec_dot_iq2_xs_q8_K | 0x00000000000a6d40 | b🔴 假把戏 (桩函数·直通标量地狱)
ggml_vec_dot_iq2_xs_q8_K_generic | 0x000000000003d140 | b🟡 纯标量 (无内耗·但无向量加速)
ggml_vec_dot_iq2_xxs_q8_K | 0x00000000000a6d80 | b🔴 假把戏 (桩函数·直通标量地狱)
ggml_vec_dot_iq2_xxs_q8_K_generic | 0x000000000003cec0 | b🟡 纯标量 (无内耗·但无向量加速)
ggml_vec_dot_iq3_s_q8_K | 0x00000000000a6dc0 | b🔴 假把戏 (桩函数·直通标量地狱)
ggml_vec_dot_iq3_s_q8_K_generic | 0x000000000003df00 | b🟡 纯标量 (无内耗·但无向量加速)
ggml_vec_dot_iq3_xxs_q8_K | 0x00000000000a6e00 | b🔴 假把戏 (桩函数·直通标量地狱)
ggml_vec_dot_iq3_xxs_q8_K_generic | 0x000000000003dcc0 | b🟡 纯标量 (无内耗·但无向量加速)
ggml_vec_dot_iq4_nl_q8_0 | 0x00000000000a6e40 | b🔴 假把戏 (桩函数·直通标量地狱)
ggml_vec_dot_iq4_nl_q8_0_generic | 0x000000000003ed00 | b🟡 纯标量 (无内耗·但无向量加速)
ggml_vec_dot_iq4_xs_q8_K | 0x00000000000a6e80 | b🔴 假把戏 (桩函数·直通标量地狱)
ggml_vec_dot_iq4_xs_q8_K_generic | 0x000000000003f0c0 | b🟡 纯标量 (无内耗·但无向量加速)
ggml_vec_dot_mxfp4_q8_0 | 0x00000000000a6f40 | b🔴 假把戏 (桩函数·直通标量地狱)
ggml_vec_dot_mxfp4_q8_0_generic | 0x0000000000038c80 | b🔴 假把戏 (桩函数·直通标量地狱)
ggml_vec_dot_nvfp4_q8_0 | 0x0000000000037e40 | b🟡 纯标量 (无内耗·但无向量加速)
ggml_vec_dot_q1_0_q8_0 | 0x00000000000a6c00 | b🔴 假把戏 (桩函数·直通标量地狱)
ggml_vec_dot_q1_0_q8_0_generic | 0x0000000000038300 | b🟡 纯标量 (无内耗·但无向量加速)
ggml_vec_dot_q2_K_q8_K | 0x0000000000096e80 | b🟢 真向量 (满血压榨硬件加速)
ggml_vec_dot_q2_K_q8_K_generic | 0x000000000003a480 | b🟡 纯标量 (无内耗·但无向量加速)
ggml_vec_dot_q3_K_q8_K | 0x00000000000975c0 | b🟢 真向量 (满血压榨硬件加速)
ggml_vec_dot_q3_K_q8_K_generic | 0x000000000003aa00 | b🟡 纯标量 (无内耗·但无向量加速)
ggml_vec_dot_q4_0_q8_0 | 0x00000000000a6ac0 | b🔴 假把戏 (桩函数·直通标量地狱)
ggml_vec_dot_q4_0_q8_0_generic | 0x0000000000038640 | b🟡 纯标量 (无内耗·但无向量加速)
ggml_vec_dot_q4_1_q8_1 | 0x00000000000a6b00 | b🔴 假把戏 (桩函数·直通标量地狱)
ggml_vec_dot_q4_1_q8_1_generic | 0x0000000000038980 | b🟡 纯标量 (无内耗·但无向量加速)
ggml_vec_dot_q4_K_q8_K | 0x0000000000098840 | b🟢 真向量 (满血压榨硬件加速)
ggml_vec_dot_q4_K_q8_K_generic | 0x000000000003b740 | b🟡 纯标量 (无内耗·但无向量加速)
ggml_vec_dot_q5_0_q8_0 | 0x00000000000a6b40 | b🔴 假把戏 (桩函数·直通标量地狱)
ggml_vec_dot_q5_0_q8_0_generic | 0x0000000000039080 | b🟡 纯标量 (无内耗·但无向量加速)
ggml_vec_dot_q5_1_q8_1 | 0x00000000000a6b80 | b🔴 假把戏 (桩函数·直通标量地狱)
ggml_vec_dot_q5_1_q8_1_generic | 0x0000000000039580 | b🟡 纯标量 (无内耗·但无向量加速)
ggml_vec_dot_q5_K_q8_K | 0x00000000000a6c40 | b🔴 假把戏 (桩函数·直通标量地狱)
ggml_vec_dot_q5_K_q8_K_generic | 0x000000000003bf40 | b🟡 纯标量 (无内耗·但无向量加速)
ggml_vec_dot_q6_K_q8_K | 0x0000000000098f80 | b🟢 真向量 (满血压榨硬件加速)
ggml_vec_dot_q6_K_q8_K_generic | 0x000000000003c9c0 | b🟡 纯标量 (无内耗·但无向量加速)
ggml_vec_dot_q8_0_q8_0 | 0x00000000000a6bc0 | b🔴 假把戏 (桩函数·直通标量地狱)
ggml_vec_dot_q8_0_q8_0_generic | 0x0000000000039a40 | b🟡 纯标量 (无内耗·但无向量加速)
ggml_vec_dot_tq1_0_q8_K | 0x00000000000a6ec0 | b🔴 假把戏 (桩函数·直通标量地狱)
ggml_vec_dot_tq1_0_q8_K_generic | 0x0000000000039b80 | b🟡 纯标量 (无内耗·但无向量加速)
ggml_vec_dot_tq2_0_q8_K | 0x00000000000a6f00 | b🔴 假把戏 (桩函数·直通标量地狱)
ggml_vec_dot_tq2_0_q8_K_generic | 0x000000000003a2c0 | b🟡 纯标量 (无内耗·但无向量加速)
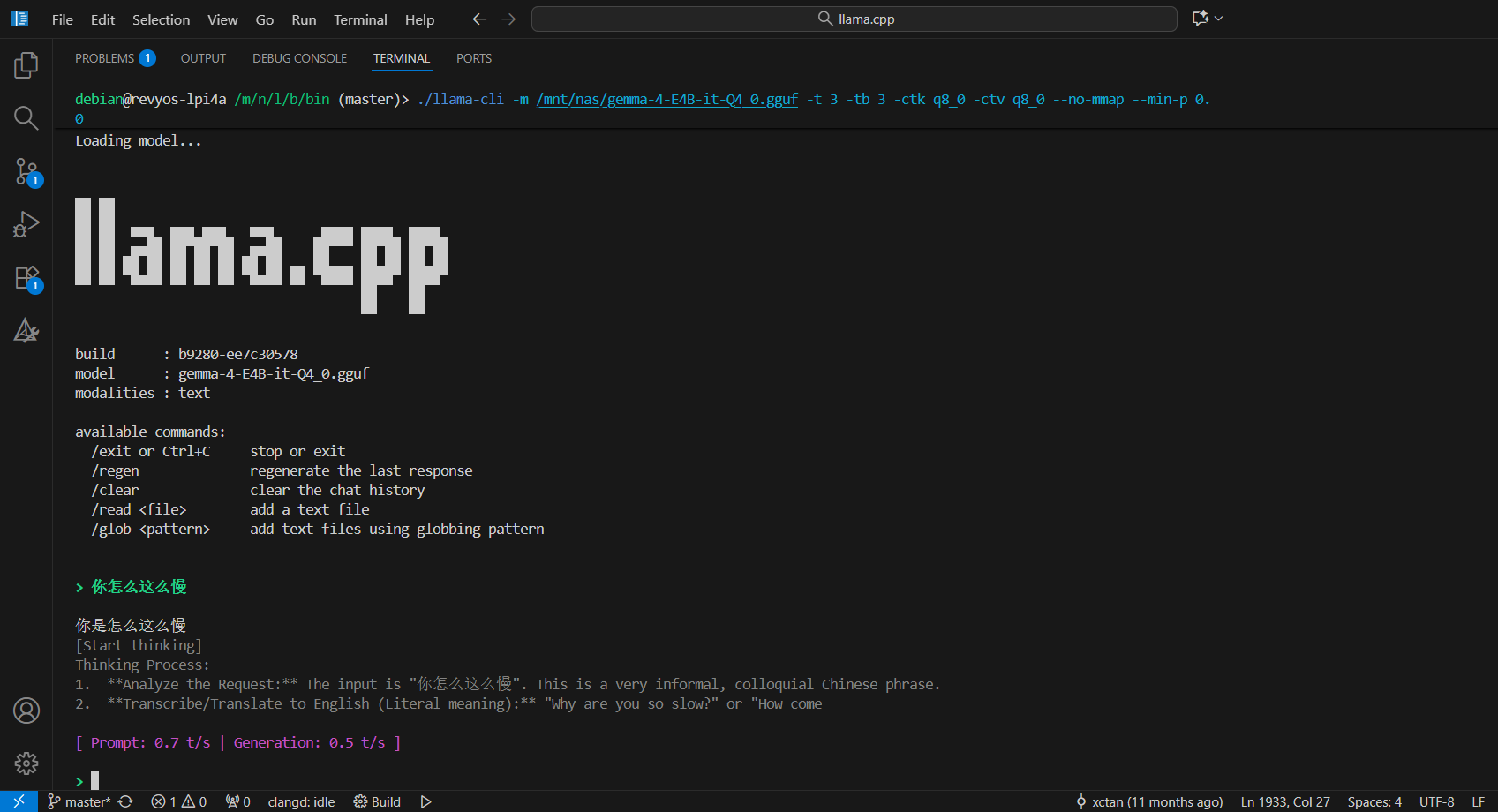
测试多个芝麻量化后的模型后得到结论:Q4_0因为结构简单,只用标量函数计算,速度就可以打平向量计算的Q4_K_M,Q4_K_M结构更复杂,数据量大。这两种格式的同规模模型速度都是0.4t/s。对于Q4_K_S和UD-Q4_K_XL,它们含有Q5_K参数,Q5_K没有向量函数,速度降低到0.3t/s。
2更:
翻了一下llama.cpp代码,向量函数检查结果和宏定义__riscv_xtheadvector(由编译参数GGML_XTHEADVECTOR控制)一致,llama.cpp现在对向量的支持比较简陋,开向量指令也就图一乐,不想自己写代码就得换其他推理软件试试